
{kind=link}
PENGERTIAN
Web Crawler atau yang sering kita kenal dengan sebutan Web Spider atau Web Robot merupakan suatu aplikasi dimana kita dapat membandingkan beberapa web yang terdapat di internet Web Crawler berkerja secara otomatis dengan membandingkan beberapa alamat website yang sering dikunjungi dan akan secara otomatis menyimpan semua bagian file yang terdapat didalamnya dalam folder komputer kita.
Nah saya akan mereview mengenai web crawler yang akan saya gunakan yaitu :
selanjutnya setelah kita mendapatkan software web crawler tersebut kita harus menginstalnya terlebih dahulu:

Setelah itu kita dapat menggunakan web creawler tersebut untuk penganalisaan data pada web clawler dan kita bisa memvalidasi kode HTML dan kita juga bisa mengumpulkan alamat e-mail website yang kita analisa.
web crawling atau spidering adalah proses mengunjungi setiap dokumen pada web clawler.

Saya menggunakan software ini karena software ini mudah di temukan dan software ini juga sangat mudah digunakan untuk menganalisa WebSite yang akan akan kita analisa.
· Kelebihannya :
1. Mengetahui detail lebih banyak tentang web yang kita inginkan
2. Ukuran filenya kecil
3. Mudah di gunakan
4. Proses penganalisaan cepat
· Kekurangannya :
1. Hanya 15 hari ( trial )
Nah saya akan mengajak kalian untuk mengetahui cara kerja win web creawler yang telah saya install tadi.
Misalnya kita akan mengecek situs website makanan cepat saji DOMINO PIZZA.
Pertama-tama kita harus memilih command button New yang terdapat di pojok kiri halaman awal web clawler.

Setelah itu akan muncul tampilan halaman sebagai berikut:

Pada gambar source yang terpilih adalah

 sedangkan seharusnya source yang kita gunakan adalah
sedangkan seharusnya source yang kita gunakan adalah disini kita memilih source WebSite / Dirs karena kita akan menganalisan berdasarkan WebSite.
Oke, Website resmi restoran cepat saji solaria sudah dapat kita masukkan karena setelah kita memilih source WebSite / Dirs tampilan menjadi:

Ketikan Website resmi DOMINO PIZZA pada kolom Starting Address
Tidak lupa juga kita harus menceklis semua Save Data in Folder dan memilih Save Data in csv Format (“url”,”title”) seperti berikut :
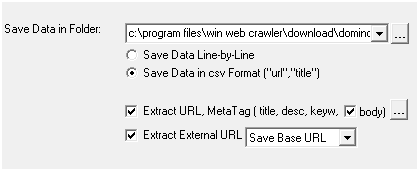
Dan kemudianpilih OK untuk memulai menganalisa website yang telah kita masukkan tadi.
Kita harus menunggu beberapa saat hingga web crawler yang sedang bekerja selesai / finished, dan ketika setesai tampilan akan menjadi seperti ini :


isi dari folder tersebut data mengenai website yang telah dianalisa.

Dalam Folder dominos.com terdapat URL dan MetaTag
dari hasil analisa tadi. dan dalam URL tersebut berisikan seluruh URL yang dimiliki domino pizza seperti berikut ini:
